There is a moment most security engineers know well. You are six weeks into a data compliance push, things are moving fast, and then something shifts. A policy that should take an afternoon to implement starts pulling threads. One access rule breaks two downstream reports. The data inventory that made sense at the start is now duct-taped together with overrides. Instead of protecting, you are firefighting. Here is a more recent, painful example from 2025: the Fortinet Data Security Report found 77% of organizations experienced an insider-related incident in the last 18 months, and despite security budgets rising a staggering 72%, 41% of those companies still lost millions to data loss incidents. The consequences can be brutal, nearly half of organizations reported losses between $1 million and $10 million per incident.
It usually traces back to the same place: the project started at the block button, not the data map. And that is precisely where lineage-first protection offers a fundamentally better approach.
The rush to block is costing more than we admit.
Failure Factor | Why It Breaks | The Real Impact |
Poor visibility into data flow | Blind policies block safe data or miss risky pipelines | Breach containment takes 43 days longer (IBM 2024) |
Weak early planning | No data map means rules are guesses | Compliance failure leads to €2.7B in GDPR fines (2024) |
Missing data lineage | Security teams have no map of where sensitive data lives | 80%+ of exfiltrated data is fragmented and invisible to legacy DLP |
False-positive fatigue | 90% reduction possible with lineage, but legacy tools lack it | Thousands of wasted analyst hours; real threats buried in noise |
Research consistently shows that inadequate data understanding is one of the leading causes of DLP program failure. Poor visibility into data movement made early, or not made at all, compounds into months of access rework downstream. Bad policies, wrong classification labels, and insufficient tooling rarely cause the failures we think they do.
But the most damning statistic? Legacy DLP tools miss roughly 70% of incidents involving derivative or transformed data because they rely on static content matching. Let that sink in. They miss data that has been copied, pasted, renamed, or edited—which is exactly how employees work every single day. Even more concerning: fewer than 20% of organizations can trace the full path of sensitive data through their environment.
These are not edge cases. They are patterns. And they are exactly what lineage-first protection exists to prevent.
What a data lineage map actually does
A lineage session before blocking is not overhead. It is intelligence.
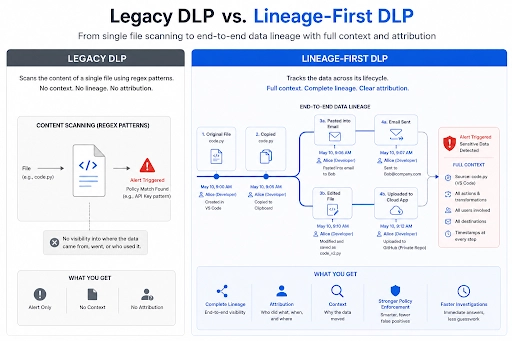
Consider the difference between a legacy tool and a lineage-aware one:
DLP Approach | How It Works | The Hidden Flaw |
Legacy DLP (Block-First) | Regex, keywords, file fingerprints | A slight reformatting bypasses detection |
Lineage-First DLP | Tracks origin, transformations, copies | Understands context, not just content |
Mapping data flows, even loosely, forces questions to the surface that block rules cannot answer cheaply. Where does sensitive data actually live? Who touches it? What transforms it? Where does it land after processing? What happens when this pipeline duplicates PII? How does that join affect classification?
These questions have cheap answers on a lineage diagram and expensive answers after a breach. Therefore, the data map is not a compliance artifact. It is where real protection starts.
A data security leader at a major financial institution described this dynamic precisely. When building new DLP controls, the starting point is not the policy engine but the column-level lineage graph. Tables get mapped, joins get documented, and transformation boundaries get argued over. Only after that visibility does the first block rule get written.
As one security engineer put it in a 2025 discussion on modern DLP: “DLP answers: ‘Something bad just happened.’ Lineage answers: ‘Here is exactly how it happened, where it came from, and what touched it along the way.'”
With most DLP tools, however, that discovery phase disappears entirely. The speed is seductive: select a checkbox and block all SSNs in seconds. But the tool makes every assumption silently, embedded in the policy. The first time you see its blind spots is during an audit, and that is the most expensive place to discover a misconfiguration.
How Data Lineage Actually Works (Visually)
Before we go further, it helps to understand what
data lineage actually looks like in practice for endpoint and email environments. Here is a simplified illustration of how lineage tracks sensitive data across a modern workplace:
Unlike a static data map, modern lineage‑first DLP is dynamic and real‑time. It automatically captures the actual flow of data as it happens across network traffic, endpoint activity, and email systems—including transformations, copies, and context shifts. For example:
- Endpoint lineage tracks when a user copies a customer list from a CRM, pastes it into a note‑taking app, or uploads a financial report to an unmanaged SaaS tool.
- Network lineage follows that same data as it travels across corporate proxies, API calls to OpenAI, file shares, or external cloud storage.
- Email lineage records every attachment, forwarded thread, pasted snippet, and external recipient, even if the original file is renamed or embedded inside another document.
Together, these provide a complete, contextualized view of how sensitive data leaves your controlled environment. Not just what left, but how it left, who moved it, what tool they used, and whether the destination was safe. This is the difference between a static policy engine and a lineage‑first system that actually understands modern data movement.
Lineage-first DLP has a name now and it is becoming standard
The industry now has a growing term for this: data discovery-first DLP. It separates the visibility and enforcement phases intentionally. In the discovery phase, teams map and classify every data pipeline before any block rules get configured. Once lineage reaches agreement, enforcement starts from a shared, explicit foundation.
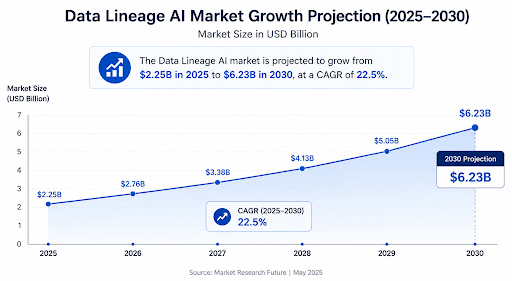
The data lineage AI market itself is exploding—projected to grow at a CAGR of 22.6%, from $2.25 billion in 2025 to $6.23 billion by 2030. Major platforms like Netskope have rolled out new Data Lineage capabilities to track data provenance from source to destination, providing a verifiable audit trail that moves with the data itself.
Gartner has written extensively about
data lineage as one of the most critical capabilities for modern DLP programs. The pattern is simple: map your data before you block your data.
As one framing puts it, lineage is “source control for your data’s journey.” Consequently, transformation paths, field-level sensitivity, and downstream dependencies get captured as a living artifact, not buried in a spreadsheet no one updates. This is, at its core, lineage-first protection in practice.
The problem with block-first at scale
Block-first DLP, which means writing access policies from assumed data locations, works beautifully for static, well-documented systems. It breaks down in modern data stacks.
When a DLP tool has no lineage to anchor to, it makes assumptions. Those assumptions compound. Consider the difference between endpoint-based data (local files, USB copies, email attachments, clipboard pastes on employee laptops) and server-based data (database tables, cloud storage buckets, data warehouse partitions). A block‑first policy might successfully stop a sensitive file from being copied to a USB drive. But without lineage, it has no idea that the same data lives on a misconfigured server bucket, or that an employee pasted a fragment of that file into a Slack message. The tool assumes its job is done. Meanwhile, the data has already moved through three other channels.
Consider the Uber 2016 breach. The company never had a real data lineage view. Attackers accessed 57 million user records and leaked license numbers of 600,000 drivers. The security team had no map of where sensitive data lived or how it moved. The DLP rules that existed blocked the wrong things entirely. The company paid $148 million in settlements and its former CSO was sentenced to three years of probation for covering it up. The breach cost was massive—but the cover-up cost even more.
For a modern, 2025-era perspective: the rise of AI tools has only deepened this crisis. Security teams report that traditional DLP fails to detect data pasted into ChatGPT or other AI prompts, which is quickly becoming one of the largest threat vectors. The Stanford 2025 AI Index Report recorded a 56.4% year-over-year increase in AI privacy incidents.
This is why the data security community has been converging on a clear principle: track lineage first, block second. Understand the system before you restrict it. Get the data flows right before the enforcement starts running. In short, map before you block.
What lineage-first looks like in practice?
Whether you use automated lineage tools or a human data governance team, the pattern that leads to effective DLP is remarkably consistent.
Start by monitoring the movement of data from the source: the endpoints. The endpoint is where AI agents act, GenAI gets data, SaaS or private apps are accessed, browsers upload files, and sensitive information moves across tools your security stack may not fully see. Traditional endpoint tools detect malware. Legacy network security inspects traffic. DLP enforced static policies. VPNs trusted networks. None were built for a world where an AI agent can read, summarize, copy, upload, or act on behalf of a user.
Consider what actually happens on a modern endpoint:
Lineage-first DLP starts here, at the endpoint, because the endpoint is where data first becomes actionable. Track what leaves, where it goes, and how it transforms—from the first click to the final destination.
From there, map column-level lineage explicitly. Where does each sensitive field originate? What transforms it? How many downstream tables depend on it? What happens if you block access at this point? This is the data map phase. It does not need to be perfect, but it needs to exist.
Once you have lineage visibility, classify based on actual usage. Apply sensitivity labels informed by how data moves and transforms, not by where documentation says it should live. A file named “test_business_ppt” that lives inside ChatGPT is sensitive regardless of its name.
After that, write policies against lineage, not locations. Block access at the source when possible, at transformation points when necessary, but never without understanding downstream impact. Each rule should be something you can explain from the map.
Finally, treat lineage as a living document. Data pipelines will evolve, and the map should evolve with it consciously, not through the accumulation of overrides. That is the core promise of lineage-first DLP.
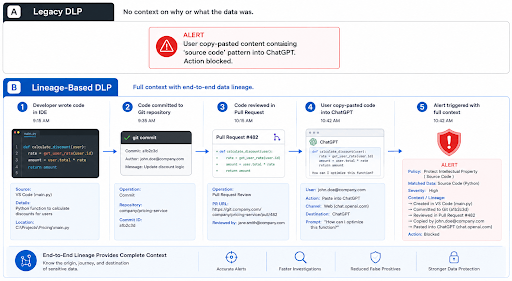
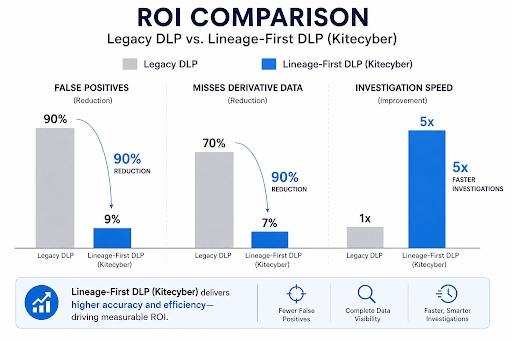
A visual comparison: How Legacy DLP vs. Lineage-Based DLP Handle an Incident
This is where the difference becomes tangible:
The difference is the difference between blocking and understanding. With
data lineage, security analysts don’t ask “What happened?”—they ask “Why did it happen?” and “What else is connected to this?” Incident investigations that once took hours can be resolved in minutes when full
data lineage and user behavior are visible.
The tools like Kitecyber are catching up to the principle.
What is interesting about the current moment in data security is that the best DLP platforms are now being designed around this principle, not against it.
We built Kitecyper following the same principle. Rather than relying on static content scanning or rigid rule sets, its platform is built on a data lineage-first architecture enhanced with AI. Organizations using this approach report a 90% reduction in false positives and 5x faster incident investigations compared to legacy DLP systems. Kitecyper’s lineage engine continuously maps how sensitive data moves across cloud apps, endpoints, and internal pipelines, tracking transformations, copies, and user interactions in real time. When a potential leak occurs, security teams see the complete journey: where the data originated, what touched it, and where it was headed. This turns hours of forensic reconstruction into minutes of verified understanding.
That is the data map phase, now inside the DLP console. Moreover, it reflects a broader shift: platforms that separate discovery from enforcement, generate lineage before generating policies, and maintain context across the full lifecycle of data movement. The idea that you can see where your data goes and have a complete dependency map emerge before any blocking starts is becoming table stakes for serious DLP programs. Kitecyper is proof that lineage-first is not a theoretical advantage—it is a practical, deployable reality.
The ROI case: Why lineage-first is actually cheaper
There is a misconception that lineage-first DLP is expensive “overhead.” The data suggests otherwise.
The true cost of a breach. According to Ponemon Institute research, the average insider-related incident now costs organizations more than $15 million annually when factoring in detection, response, legal liability, and reputational damage.
The cost of legacy tools. A single data leak of 100,000 customer records can cost $21.8 million in direct and immediate costs. And with legacy DLP tools missing 70% of derivative data incidents, this is not a hypothetical risk—it is a statistical certainty at scale.
The impact of efficiency. Cutting investigation time by 50% or more—which lineage-based tools routinely achieve—directly reduces exposure, limits impact, and lowers downstream legal and regulatory costs.
When you compare the investment in lineage-first DLP against the cost of even one preventable breach, the math is not close. The question is no longer whether you can afford modern, lineage-based DLP. It is whether you can afford not to have it.
The data map was never optional.
Here is what tends to get lost in the block-versus-discover framing:
data lineage is not a tax on DLP. It is the thing that makes blocking actually work.
Programs that enforce effectively over the long run are those that mapped deliberately at the start. Time on lineage discovery, literally or figuratively, comes before the first block. Data flows get defined before policies get configured. Pipeline dependencies get agreed on before access gets restricted. Impact analyses get thought through before they get encountered during an incident.
The block button is where enforcement gets applied. The data map is where enforcement gets designed. And DLP without a map is DLP that breaks production. That is the true cost of skipping lineage-first protection: not on day one, but on day sixty, when the sales team cannot access the dashboard and the compliance ticket count exceeds the feature count and the data team spends more time whitelisting than governing.
The best data security teams have always understood this. Now, the best tools are finally starting to reflect it. So if you are rethinking how your team approaches DLP, the answer is clear: start with lineage, not with the block button. Blocking should come next and only when required.